待ち行列理論
エンジニアリングの喜びは、二重対数グラフ上に直線を見つけることにある。
—トーマス・ケーニッヒ Thomas Koenig
待ち行列理論 は、なぜ従来の開発が不必要に遅いのか、そしてそれを改善する方法についての洞察を提供します。大規模開発においては、「1つの」機能(分割前)が驚くほど巨大であることが一般的です。こうした領域では、大きなバッチや長い待ち行列が実際に存在し、それが引き起こす問題を認識することが特に重要です。自分が抱えている問題を知らなければ、それを解決することは困難です。待ち行列理論は、改善のためのいくつかの方法を示してくれます。この思考ツールは特に大規模開発に関連性が高く、従来のモデルでよく見られる大きく可変なバッチ作業は、サイクルタイムに非線形な影響を与えるため、プロセスを本当に混乱させる可能性があります。

興味深い不一致: 待ち行列理論(queueing theory)——つまり、「待ち行列を伴うシステム内で モノ がどのように流れるか」を数学的に分析する理論——は、もともと通信システムにおけるスループットの向上を目的として発展しました。通信システムは、製品開発と同様に高い変動性とランダム性を伴うものです。その結果、通信エンジニアは待ち行列理論の基本的な洞察を理解しています。しかし、通信インフラ開発(通信業界は大規模プロダクトの領域)に携わる人々は、自分たちの開発プロセスにおける平均サイクルタイムを短縮するために、この理論が適用できることをほとんど認識していません。
トヨタの人々は、統計的変動や待ち行列理論の示唆を学び、それはリーンの「平準化(leveling)」の原則に反映されています。この原則は、変動を減らすことを目的としており、より一般的には小さなバッチと短いサイクルタイムを重視し、フロー(flow) へと向かうリーンの考え方に表れています。
本題に入る前に、リーンはしばしば以下の要素に焦点を当てて説明されます:
- 小さなバッチ(作業パッケージ)サイズ
- 短い待ち行列
- 高速なサイクルタイム
つまり、「価値を素早く届けること」が強調されます。しかし、リーンはそれだけではありません。その柱となるのは、
- 人々への敬意(respect for people)
- 継続的な改善(continuous improvement)
であり、その基盤には 「リーン思考のマネージャー=教師」 という考え方が存在します。
待ち行列管理(WIP制限など)は有用ですが、それは単なるツールであり、リーン思考の本質からは程遠いものです。
この後の議論を通じて、LeSS(Large-Scale Scrum)が待ち行列理論のマネジメント上の示唆をサポートしていることが明らかになるでしょう。
リトルの法則に関する誤解警報(Little’s Law Myth Alert)
待ち行列理論を深く掘り下げる前に、リーンやアジャイル開発コミュニティ(さらには一部のスケール手法)で広まっている誤解について、早めに整理しておきましょう。
多くの記事で、「リトルの法則は WIP(仕掛かり作業)を減らせば平均サイクルタイムが短くなる ことを証明している」と主張しています。しかし、それが真実ならどれほど良いことでしょうか!
残念ながら、リトルの法則の証明は、ある特定の条件や前提が成り立つ場合にのみ適用されるものです。この法則が成り立つための条件が満たされている必要があるのですが、ソフトウェア開発のような高変動性の領域では、その条件が保証されるどころか、むしろ一般的に成り立たないことが多いのです。
ソフトウェア開発におけるリトルの法則の単純な適用や誤った正当化は、Daniel Vacanti による Little’s Flaw という分析の中で、詳細に解体されています。
WIP(仕掛かり作業)を減らすことは価値のある目標であり、LeSSにおいても重要な要素です。
WIPはリーン思考におけるムダの一つと考えられています。なぜなら、
- 投資回収の遅れを招く
- 欠陥を隠してしまう
- 透明性を低下させる
といった問題を引き起こすからです。
さらに、WIPを減らすことで、組織の弱点が露呈するという側面もあります。
しかし残念ながら、ソフトウェア開発において、WIPを減らせば平均サイクルタイムが自動的に短縮されるとは限りません。
短いサイクルタイムで競争する(Compete on Shorter Cycle Times)
リーンなプロダクト開発組織は、最短の持続可能なサイクルタイムで価値のスループットを最大化することに焦点を当てています。そのため、システム全体のスループット(throughput) に着目し、個々の人の忙しさ(busyness)に囚われません。
リーン思考の生みの親であるトヨタは、人々に過度な負担をかけることなく、より短いサイクルタイムを実現することの達人です。
プロダクト開発におけるサイクル(またはサイクルタイム)の例
- 「コンセプトからキャッシュまで」:1つのリリースを完了するまでの期間
- 「コンセプトから完了まで」:1つの機能が完了するまでの期間
- 「潜在的に出荷可能な時間」:どれくらいの頻度で出荷できるか?
- 「コンパイル時間」:ソフトウェア全体をコンパイルするのにかかる時間
- 「パイロット準備完了から納品まで」:パイロット版の準備から実際の納品までの時間
- 「テスト環境へのデプロイ時間」:組み込みハードウェアなどへのデプロイ時間
- 「分析・設計にかかる時間」
これらのサイクルタイムを短縮することで、開発のスピードと市場競争力を向上させることができます。
リーンにおける主要業績指標(KPIs)は、作業者の稼働率や忙しさには焦点を当てません。
むしろ、スループットやサイクルタイム(throughput cycle time)に重点を置いています。
計測に対する注意点
ただし、注意が必要です。指標を測定すると、システムが誤った最適化(サブオプティマイズ)を引き起こし、「良いスコア」を得るために操作されるリスクがあります([Austin96])。
特に低レベルのプロセスサイクルでは、この問題が顕著になります。一方で、
- 「潜在的に出荷可能なサイクルタイム」
- 「注文からキャッシュ化(order to cash)」
- 「注文から納品(order to delivery)」
などの高レベルのサイクルタイムは、より本質的に重要です。
半分の時間で開発できるとしたら?
もし、持続可能なペースで、人に過度な負担をかけずに、
開発や納品を 半分の時間、あるいは1/4の時間で実現できる としたら?
そして逆に、遅延のコスト はどれほどの影響を与えるでしょうか?
スピーディな納品によるメリットを考えてみてください:
- ライフサイクル全体の利益向上
- 新たなビジネスチャンスの獲得
- 競争への迅速な対応
- イノベーションの加速
ほとんどの企業にとって、これらは 計り知れない競争優位 となるでしょう。
「半分の時間」は「半分のコスト」ではない
人々が「開発期間を半分に短縮する」と聞くと、
「2倍のプロダクトや機能をリリースできる、つまり2倍の効率化が可能」と考えがちです。
しかし、そこにはトランザクションコスト(各サイクルに伴う間接費用)という要素があります。
頻繁に出荷すれば、テストやデプロイコストが増加するかもしれません(あるいは、そうならないかもしれません)。
「半分の時間」は「2倍のコスト」でもない
「頻繁な出荷はコスト増につながるのでは?」と考えるかもしれません。
しかし、サイクルタイム、トランザクションコスト、効率の間には微妙な関係が存在します。
これは、トヨタやリーン企業が驚異的な効率を実現する秘密の一つです。
待ち行列管理(Queue Management)
サイクルタイムを短縮するための戦略は豊富にあります。
リーンやアジャイルのプラクティスには、数多くのスキルフルな手法が含まれています。
その中でも、本セクションで取り上げるのは 「待ち行列管理(Queue Management)」 です。
サイクルタイム短縮のための待ち行列管理(Queue Management to Reduce Cycle Time)
「待ち行列(Queue)は製造業にしか存在しないため、待ち行列理論や待ち行列管理はプロダクト開発には適用できない」
これはよくある誤解です。
前述のように、待ち行列理論は製造業から生まれたのではなく、通信システムのスループット改善のためにオペレーションズリサーチの分野で発展しました。
さらに、多くの開発組織(特にリーンやアジャイルを採用している企業)は、待ち行列理論の洞察を活用した待ち行列管理を、
- プロダクト開発
- ポートフォリオマネジメント
の両方に適用しています。
MIT & スタンフォードの研究による調査結果
MITとスタンフォードの研究者による調査では、以下の結論が得られました。
このアプローチ(ポートフォリオおよびプロダクトマネジメントにおける待ち行列管理)を採用した事業部は、平均開発期間を30%〜50%短縮できた。
[AMNS96]
プロダクト開発とポートフォリオ管理における待ち行列の例
開発プロセスやポートフォリオマネジメントにおいて、どのような待ち行列が存在するでしょうか?
- ポートフォリオ内のプロダクトやプロジェクト(優先度決定待ち)
- 1つのプロダクトに追加する新機能(開発開始待ち)
- 設計待ちの詳細な要件仕様
- コーディング待ちの設計ドキュメント
- テスト待ちのコード
- 1人の開発者が書いたコードが、他の開発者のコードと統合されるのを待っている状態
- 統合待ちの大規模コンポーネント
- テスト待ちの大規模コンポーネントやシステム
待ち行列の可視化と適切な管理は、サイクルタイム短縮と開発効率向上に直結する重要な要素です。
従来の開発における待ち行列とその問題点(Queues in Traditional Development and Their Problems)
従来の逐次開発(ウォーターフォール型)では、多くの未完了の作業が蓄積する待ち行列(WIP キュー)が発生します。たとえば、
- プログラミング待ちの仕様書
- テスト待ちのコード
といったものが典型的な例です。
さらに、WIP キュー だけでなく、以下のようなリソース制約による待ち行列(Shared-Resource Queues) も存在します。
- 高額なテスト機材やラボの利用待ち
- 専門スキルを持つエンジニアのスケジュール待ち
なぜ待ち行列が問題なのか?
1. キューがなければフロー(Flow)に近づく
リーンの原則では、価値を遅延なく提供すること(Flow) が理想とされます。
キューが存在することで、フローを阻害し、納品の遅れを生む のです。
WIP キューの問題
WIP キュー(仕掛かり作業の待ち行列)は、ソフトウェア開発では見えにくい という特徴があります。
なぜなら、それらは コンピュータのディスク上のデータ として存在し、物理的な在庫のように目に見えるわけではないからです。
しかし、それらは確実に存在し、多くの問題を引き起こします。
WIP キューの主な問題点
- サイクルタイムを長引かせ、価値提供を遅らせる → 収益性の低下 につながる
- 部分的に完了した在庫(仕様書、コード、ドキュメント…)が積み上がる → まだ ROI が発生しない投資になっている
- 不具合(バグ)を隠し、同じミスを繰り返す原因となる
- 例:統合されていないコードが蓄積し、後になってバグが発覚する
- 変更への対応コストが増大する
- 例:1年かけて開発した「必須機能」を市場の変化により削除 → すでに投資したコストが無駄になり、再計画に数週間かかる
- 例:高 WIP により新機能の追加が遅れる
このように、WIP キューを削減することで、システム改善につながる副次的な効果 が期待できます。
リソース制約による待ち行列(Shared-Resource Queues)
WIP キューと異なり、リソース制約による待ち行列は「問題として認識されやすい」 という特徴があります。
なぜなら、開発のボトルネックになり、作業を直接的に遅らせる からです。
例:
- 「新しいコードをテストラボのプリンタで試験したい。でも、いつ空くかわからない…」
- 「この特殊なテストツールは1台しかないから、順番待ちになる…」
このように、共有リソースの待ち行列は、開発スピードを大幅に低下させ、フィードバックの遅れを引き起こします。
プランA:待ち行列を管理するのではなく、排除する(Plan A: Eliminate, Rather than Manage, Queues)
結論から言えば、待ち行列(キュー)は基本的に「問題」である ことがほとんどです。
この前提を受けて、多くの人は次のように考えるかもしれません。
「まずはバッチサイズとキューサイズを減らすことが対策の第一歩だ!」**
確かに、これは待ち行列管理の典型的な戦略ではあります。
しかし、ここで考えるべきは、ゴルディアスの結び目(Gordian Knot)を断ち切るような、根本的な解決策 です。
待ち行列の問題を解決する「プランA」
この章の後半では、バッチサイズとキューサイズの管理によるサイクルタイムの短縮 について詳しく掘り下げます。
しかし、それは 「プランB」 にすぎません。
本来、最初に取り組むべきなのは 「プランA」 です。
プランAとは、「待ち行列を完全に根絶すること」
そのために、組織のシステム自体を変える。
- 組織の仕組み
- 開発の進め方
- ツール
- プロセス
- プラクティス
- ポリシー
など、システム全体を変革することによって、キューの発生を未然に防ぐ。
待ち行列を減らすのではなく、そもそも待ち行列が不要な仕組みを作ることが、最も強力な解決策である。
システムの外側から考え、待ち行列をなくす(Think Outside the Current Box)
キュー(待ち行列)をなくし、サイクルタイムを短縮するには、既存の「箱の中」の思考を超えて、
システム自体を変えることが重要 です。
具体的には、ボトルネックを取り除き、キューを発生させる要因をなくす ことです。
キューが生まれる原因は、開発システムの構造やツールの性質そのものにあるかもしれません。
それならば、システムを根本から変えれば、キューは不要になります。
従来型の逐次開発の問題
例えば、現在の開発システムが
「職能別グループ(単一専門職)」 に基づく逐次開発の仕組みだったとします。
典型的な流れ:
- アナリスト → 仕様書を作成し、プログラマーへ
- プログラマー → コードを書き、テストチームへ
- テストチーム → テストを行い、デプロイメントチームへ
- デプロイメントチーム → 本番環境へリリース
このような 「箱の中」の発想では、待ち行列(WIP)が発生し続けます。
多くの人は、WIP制限を設けたり、キューサイズを小さくする ことで対策しようとしますが、
これは 「既存のシステムの二次的な症状」に対処しているにすぎません。
根本的な解決策
サイクルタイムを劇的に短縮するには、
この従来型システムを「捨てる」ことが最も効果的です。
LeSS(Large-Scale Scrum)の考え方に基づく解決策:
クロスファンクショナルな「フィーチャーチーム」 を導入
分析、開発、テストを一つのチームで完結 し、グループ間のハンドオフを排除
受け入れテスト駆動開発(ATDD) の自動化
継続的デプロイメントの自動化
このように逐次開発から並行開発へ移行すれば、WIPキューは消滅 します。
これこそが、LeSSが目指す「根本原因を解決する組織設計」です。
偽りの待ち行列削減(Fake Queue Elimination)
「待ち行列をなくす」と言いながら、
実はただの「見かけ上の削減」にすぎない というケースもあります。
例えば:
- Aの作業中に、B、C、D、Eの作業も並行して進める
- つまり、高いマルチタスクとリソースのフル活用(超高負荷)
- これで「キューが減ったように見える」
しかし、これは 本質的な問題解決ではなく、リーンのムダを増やすだけ です。
実際には、平均サイクルタイムが増加し、WIPが悪化する ことが待ち行列理論で示されています。
プランB:待ち行列を排除できない場合の管理方法(Manage Queues When You Can’t Eliminate Them)
理想的には、LeSSの導入によって、従来型のWIP(仕掛かり作業)のキューを完全に排除することが可能 です。
具体的には:
クロスファンクショナルなフィーチャーチーム を導入
受け入れテスト駆動開発(ATDD) を実施
継続的デプロイメント(CD) を実現
このアプローチにより、プランA(システム自体を変えることで待ち行列を根絶する) が機能します。
これが LeSSにおける理想的なソリューション です。
それでも待ち行列が残る場合
しかし、現実的には以下のような理由で待ち行列を完全には排除できないこともあります。
- 共有リソースのキュー
- 例:テストラボの順番待ち、特定のハードウェア環境の利用待ち
- プロダクトバックログにおける機能リクエストのキュー
- プロダクトバックログは、ある意味で「待ち行列」そのもの
- WIPキュー
- (1) プランAをすぐには実現できない(大規模な組織変革には時間がかかる)
- (2) ツールや技術(手動→自動化の移行など)が遅れている
プランB:待ち行列を管理し、サイクルタイムを短縮する
完全には排除できないキューが残る場合、プランBとして「待ち行列管理」によってサイクルタイムを短縮 できます。
プランBの基本戦略
キュー内のバッチサイズを減らす
WIPリミットを設定し、待ち行列のサイズを小さくする
各バッチを均等なサイズにする
たとえば…
- テスト環境のキューがある場合 → 小さな単位でテストし、バッチを減らす
- プロダクトバックログが膨大な場合 → 機能ごとのバッチサイズを小さくする
- 大規模リリースを分割 → 小規模で頻繁なリリースにする
このように、バッチサイズとWIP制限を最適化することで、サイクルタイムを改善する ことが可能です。
LeSSでは、小さなバッチとは、1つのスプリントで開発するアイテムや機能の単位を小さくすること を意味します。
また、均等なサイズのバッチとは、それぞれのアイテムの開発コスト(工数)が大体同じくらいになること を指します。
待ち行列理論(Queueing Theory)
待ち行列を 根絶する ことで管理するのは、新しい視点やシステム変更が必要になるものの、理論的に難しいことではありません。
しかし、待ち行列がどうしても存在する場合 は、待ち行列理論 という思考ツールを使って適切に対処することが有効です。
プロセスを評価するための正式なモデル(A Formal Model for Evaluating Processes)
「小さなバッチで、均等なサイズの待ち行列を作るとサイクルタイムが短縮される」
この主張をそのまま受け入れることもできますし、疑問を持つこともできるでしょう。
いずれにせよ、この考え方は単なる意見ではなく、数学的なモデルに基づいたものであり、実証可能な理論である ことを知っておくのは有益です。
実際、開発プロセスのいくつかの側面については、正式なモデルを使って論理的に分析することが可能 です。
例えば、以下の仮説を考えてみましょう。
仮説1:
ウォーターフォール(Vモデル)のような逐次開発では、大きなバッチをグループ間で受け渡す方が最も速い。
仮説2:
個人やグループの稼働率を高くし、多くのプロジェクトを並行して進める(マルチタスク)ほうが最も速い。
このような仮説がサイクルタイムの短縮に本当に寄与するのか?
それを明らかにするためには、待ち行列理論に基づいた分析 が有効です。
実は、待ち行列理論はそれほど複雑なものではありません。
この後、具体的なシナリオを使って、基本的な考え方を説明していきます…
待ち行列を伴う確率システムの特性(Qualities of a Stochastic System with Queues)
待ち行列を伴う確率システムの特性(Qualities of a Stochastic System with Queues)
ロサンゼルスやベンガルールのラッシュアワーを想像してください。
奇跡的に事故はなく、すべての車線が開いています。
交通は混雑して遅いものの、なんとか流れています。
しかし、短時間のうちに3つの主要な4車線の高速道路で事故が発生し、3車線が閉鎖 されました(合計12車線中、9車線のみが開放)。
すると、瞬く間に都市全体が「フェーズシフト」して「グリッドロック(完全な交通麻痺)」に陥ります。
さらに問題なのは、事故が解消されてもすぐには渋滞が解消されないこと です。
30〜60分の車線閉鎖で発生した膨大な待ち行列が、解消されるまでに「非常に長い時間」がかかる のです。
この現象から得られる重要な洞察
非線形性(Nonlinear)
50%未満の交通量ではスムーズに流れる(ほぼ待ち行列なし)。
50%を超えると減速が顕著になり、待ち行列が急速に増加する。
利用率と待ち行列の関係は直線的ではなく、非線形である。
** 遅延と過負荷は99.99%の利用率で突然発生するわけではない(Delay and overload does not start at 99.99% utilization)**
道路が100%埋まる直前まではスムーズに流れるわけではない。
60%あたりからすでに減速し始め、待ち行列が形成される。
** 待ち行列の解消には、発生した時間以上の時間がかかる(Clearing the queue takes longer than making it)**
ロサンゼルスのラッシュアワーで45分の閉鎖が発生した場合、その渋滞が完全に解消されるには45分以上かかる。
つまり、待ち行列は短期間で生じるが、その解消には長時間かかる。
** 確率的(Stochastic)であり、決定論的(Deterministic)ではない**
到着する車の流れ、事故の発生時間、出口から出る車の割合はランダムであり、一定ではない。
これは確率的システム(Stochastic System)であり、決定論的(Deterministic)なものではない。
人間は待ち行列システムの非線形性を直感的に理解できない
私たちは一般的に「システムは決定論的であり、線形に振る舞う」と誤解しがちです。
この誤った「常識」は、待ち行列が関係する問題の分析やプロダクト開発の管理において、思考ミスを引き起こします。
例えば、プロダクト開発における典型的な誤解 「遅延は、システムが100%の負荷にならない限り発生しない」
実際には、60%程度の負荷から既にサイクルタイムが長くなり、遅延が発生し始める。
このような非線形の特性を理解することは、WIP(仕掛かり作業)キューの管理や、あらゆる待ち行列に対処する際に不可欠 です。
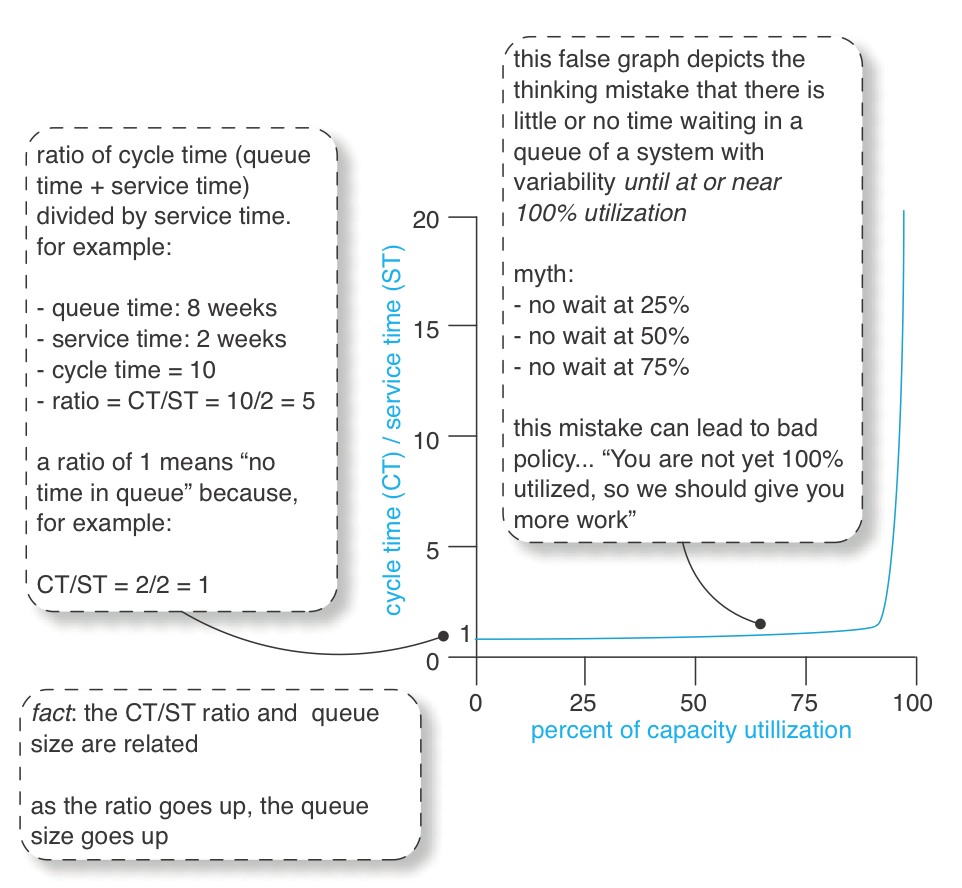
「リソース稼働率を上げればサイクルタイムが改善する」という誤解
「遅延はシステムが100%の負荷になったときに初めて発生する」という誤解があると、
リソース(人や設備)の稼働率を上げることで、サイクルタイムを改善しようとする という間違った発想に至ります。
この考え方の典型例が、マルチタスクを増やして開発者の「忙しさ」を高めること です。
しかし、これは 局所最適化の思考ミス(local-optimization thinking mistake) です。
リソース稼働率を高めると、サイクルタイムはどうなるのか?
システムに変動性(variability)が存在する 状態で、リソースの稼働率を上げると何が起こるでしょうか?
** 例:Xeroxのテストラボ**
Xeroxでは、大型デジタル印刷機(非常に高価な機器)を使用してテストを行っています。
この機器には、しばしばテストリクエストの待ち行列が発生します。
もし「待ち行列理論を正しく理解していない」 と、
マネジメントは「設備を100%フル稼働させるべき」と考えるでしょう。
しかし、現実には、このシステムには 変動性(stochastic variability)が多く存在します。
- テストの到着はランダム
- あるテストはすぐに終わるが、別のテストは異常に長時間かかる
- 機器が故障することもある
このような「確率的な変動(stochastic variability)」があるシステムでは、リソースの稼働率を上げると、かえってサイクルタイムが悪化する可能性が高いのです。

### 基本的な単一到着待ち行列システムのモデル化(Modeling a Basic Single-Arrival System with Queues)
交通渋滞、テストラボ、あるいは伝統的なプロダクト開発におけるWIP(仕掛かり作業)キューの動作は、どのように説明できるでしょうか?
前述の交通渋滞の話から、直感的な理解はあるかもしれませんが、これを数学的にモデル化するとどうなるでしょう?
M/Mシステムとは?
待ち行列理論では、M/Mシステム という標準的なモデルを用います。
M/M とは?
- 最初の “M”(Markovian):到着するリクエストの間隔が確率的(Poisson分布に従う)
- 次の “M”(Markovian):処理時間も確率的(指数分布に従う)
要するに、「現実のシステムはランダムであり、将来の状態を決定論的に予測できない」 という考え方です。
これは、交通の流れ、テストラボのリクエスト、ソフトウェア開発のWIPキューにも当てはまります。
M/M/1/∞ システムとは?
シンプルな待ち行列モデルの一つが M/M/1/∞ です。
- M/M → 到着と処理が確率的(ランダム)
- 1 → 1つのサーバー(例:1台のテストプリンター、または1つの開発チーム)
- ∞ → キューの長さが無限(現実には有限だが、基本パターンの理解には影響しない)
例えば、このモデルを使うと、1台のテストプリンター や 1つの開発チーム が待ち行列にどう影響を与えるかを分析できます。
M/M/1/∞ におけるサイクルタイムとリソース利用率の関係
このシステムでは、サーバー(例:プリンターや開発者)の利用率がどのようにサイクルタイムに影響するか を分析できます。
この時点で、非常に重要な洞察が生まれます… 利用率が増えると、待ち時間が急増する
100%に近づくほど、サイクルタイムは非線形に悪化する(「非線形の法則」)
リソースを最大限稼働させると、実際にはフローが悪化する(=誤った局所最適化)
なぜこの分析が重要なのか?
このモデルの洞察は、待ち行列理論を直感的に理解していないと見落としがちな「落とし穴」 を示しています。
例えば:
- 「開発チームは100%稼働するべきだ!」 → 誤りです!リソースの100%稼働は待ち行列を長大化させる
- 「テスト設備をフル活用すれば効率が上がる!」 → 誤りです!リソース利用率が高まると、ボトルネックが発生する
「余裕を持たせる」ことが、実はサイクルタイム短縮にとって最善策になる という示唆が得られます。
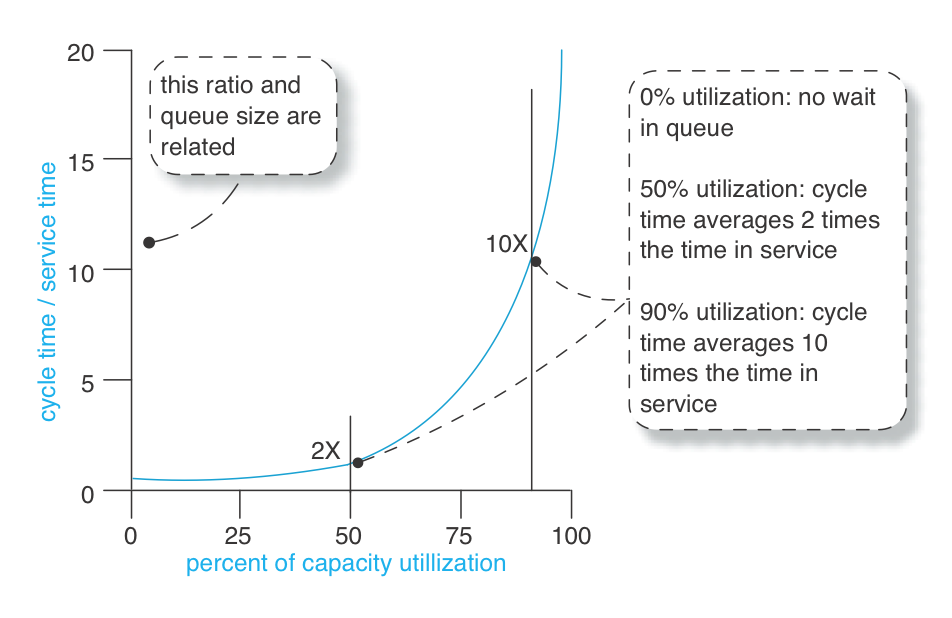
リソースの利用率が上がると、サイクルタイムは悪化する
ここで最も重要なポイントは、アイテム(例えば、要件リクエストなど)がキューに入るのは、作業者の稼働率が100%に達するよりずっと前からである という事実です。
また、特に興味深いのは、システムにおける人の利用率が上がると、サイクルタイムは短縮されるどころか、むしろ悪化する という点です。
これは、従来の経営コンサルタントや会計士が教えられてきた「リソースの稼働率を上げれば生産性が向上する」という考え方と正反対 です。 ほとんどの人はキューイング理論(待ち行列理論)に触れたことがなく、そのため、待ち行列のある確率システム(変動のある作業を行う人々)を理解する方法を知らず、思考上の誤りを犯してしまいます。
この現実世界の変動こそが、製品開発における平均的な待ち行列の長さと待ち時間を増加させているのです。
バッチシステムと待ち行列のモデル化(従来型開発)
さらに興味深い話になります(信じられないかもしれませんが…)。
基本的な M/M/1/∞ システムは、単一のアイテム(テスト、分析、プログラミングなど) が個別に到着することを前提としています。
つまり、到着するアイテムがまとまって到着する(バッチ化される)ことはない という仮定です。
しかし、従来型のプロダクト開発では、作業パッケージは実際には大きなバッチとして到着します。
例えば:
- 要件のセット
- テスト作業のまとまり
- 統合待ちのコード
また、一見「単一の要件」に見えるものでも、実際にはバッチである場合があります。
例えば、「ブラジル市場の債券デリバティブ取引を処理する」という要件は、実は複数のサブ要件の集合 です。
この最後の点は非常に重要です。
大きな要件は、それ自体がバッチであり、システムを単一の作業パッケージとして流れることはない という事実が、誤解されることがよくあります。
この 「1つの大きな要件は、実はバッチである」 という考え方は、後ほど再び取り上げます。
したがって、より単純な単一到着モデル(M/M/1/∞)(単一の作業アイテムが到着する)ではなく、M[x]/M/1/∞ システム(バッチ単位でアイテムが到着する)を考えるべきです。
このモデルの方が、従来型のプロダクト開発をより適切に表現 しています。
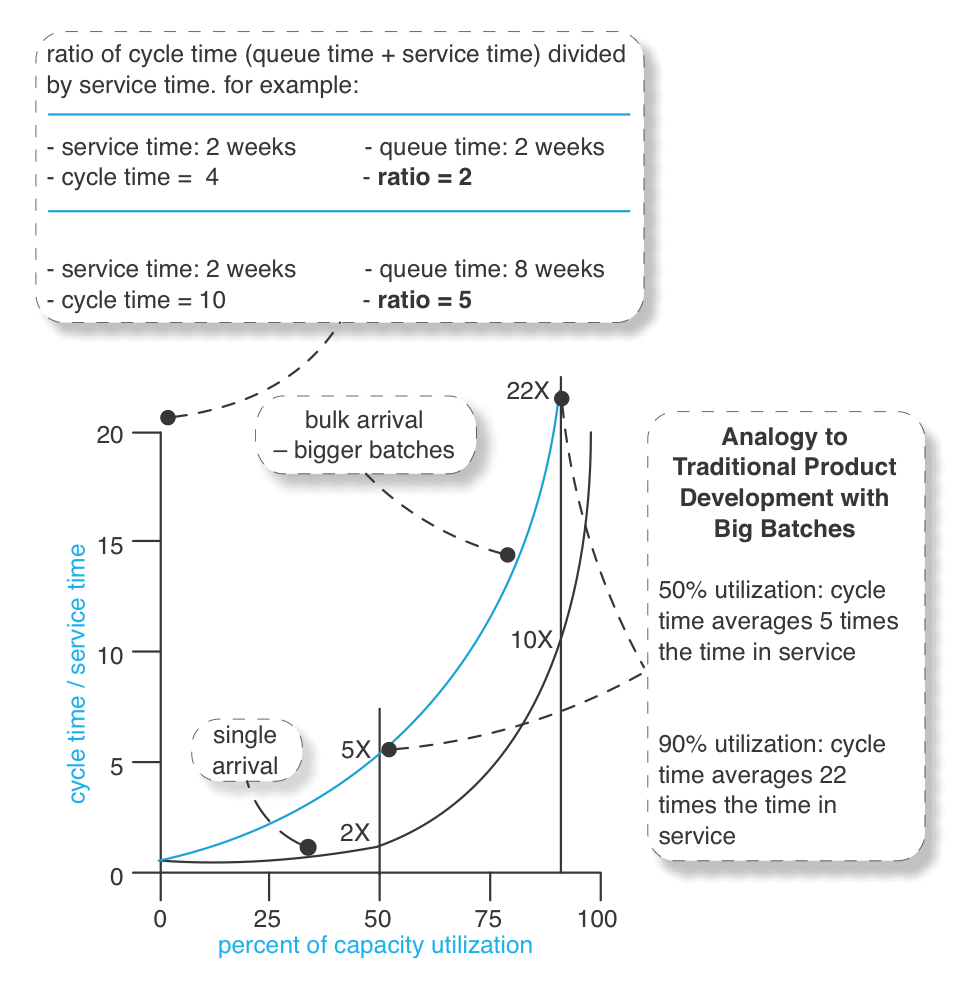
一見すると、人々は自分たちのサイクルタイムに起こった驚くべき、直感に反する影響をすぐには理解できないかもしれません。
シナリオを考えてみましょう:
ある人またはチームが現在 50% の稼働率 であり、通常は 小さな単一の要件 をランダムな間隔で受け取り、それぞれのサイズには多少の変動があるとします。
ここで、ある特定の 要件X を完了するのに 実作業時間で2週間 かかると仮定します。
また、このシステムが単一到着モデル(single-arrival system) であると仮定します。
以下の表は、平均的な状況の概算を示しています。
| Arrival | Utilization | Queue Time | Service Time | Cycle Time | Ratio CT/ST |
|---|---|---|---|---|---|
| single arrival | 50% | 2 weeks | 2 weeks | 4 weeks | 2 |
次に、同じく 50% の稼働率 のチームに対して、通常よりも 大幅に大きなバッチの要件、または 「1つの」巨大な要件(実際には多数のサブ要件を含む) を渡すケースを考えます。
これらのバッチも、ある程度のランダム性とサイズの違いを持って到着するとします。
ここで、ある特定の バッチX(または単一の大要件) を完了するのに 実作業時間で20週間 かかると仮定します。
前の表を考慮すると、多くの人が 大きなバッチが到着した場合のサイクルタイム を次のように予測するでしょう。
| Arrival | Utilization | Queue Time | Service Time | Cycle Time | Ratio CT/ST |
|---|---|---|---|---|---|
| single arrival | 50% | 2 weeks | 2 weeks | 4 weeks | 2 |
| if big batch? | 50% | 20 weeks | 20 weeks | 40 weeks | 2 |
直感的な予測では、サイクルタイムへの影響は「線形」に増加すると考えがち です。
つまり、「平均して10倍の作業量をシステムに流せば、サイクルタイムも10倍になる」と予測されるでしょう。
4週間 → 40週間 という単純な増加を想定するかもしれません。
しかし、実際にはそのようにはなりません。
なぜなら、システム内にさらに大きな「変動性(variability)」が導入されるため です。
では、何が起こるのでしょうか?
50%の稼働率のとき、M[x]/M/1/∞ のシステムでは、サイクルタイムとサービス時間の比率が「5」 になります。
これに基づくと、次のような対照的な状況が予測されます。:
| Arrival | Utilization | Queue Time | Service Time | Cycle Time | Ratio CT/ST |
|---|---|---|---|---|---|
| single arrival | 50% | 2 weeks | 2 weeks | 4 weeks | 2 |
| big batch | 50% | 80 weeks | 20 weeks | 100 weeks | 5 |
状況は はるかに悪化 しました。
もちろん、これらは 平均値 であり、特定の実際のケースにそのまま適用できるとは限りません。
また、このモデルは開発プロセスを単純化した抽象的なものです。
しかし、待ち行列理論を理解し、それに基づいて行動することが、大規模開発において非常に重要である理由 がここにあります。
なぜなら、大規模なシステムはしばしば大きな要件を扱うことになり、
- 大きな作業(要件、テスト、統合など)が、大きなバッチで、ランダムなタイミングで到着する
- 作業者は常に100%稼働している(忙しくしている)ことが求められる
このような条件がそろうと、平均サイクルタイムに驚くべき影響 を与えるのです。
したがって、大きなバッチの作業がある状況で、作業者の稼働率を高めようとすることは、「超スローモーション」への処方箋である。
現実には、サイクルタイムは「超線形(super-linear)」に増加する。
この遅延と待ち行列の増大は、人間の直感に反するものです。
なぜなら、人は 待ち行列を持つ確率的システム を分析することに慣れていないからです。
多くの人は 「作業パッケージを10倍大きくしたら、システムから出るのに10倍の時間がかかる」 と考えがちですが、
そんな単純なものではない。
従来の逐次開発では、遅延はさらに悪化する
従来のウォーターフォール型開発では、各プロセスの前にWIP(仕掛かり作業)の待ち行列が存在 します。
これにより、
システム全体の変動性が増幅される
平均サイクルタイムへの悪影響がさらに拡大する
「変動性配置の法則(Law of Variability Placement)」 [HS08] によれば、
「多段階のシステムにおいて、変動性が最も悪影響を与えるのは、待ち行列を持つシステムの最初の段階である」。
これは、フェーズ1の要件分析において、大量の仕様が一括で処理される状況とまさに一致します
結論(Conclusion)
では、何が学べたでしょうか?
- プロダクト開発は待ち行列を伴う確率的なシステムであり、非線形かつ非決定論的である。
- 待ち行列を伴う確率的システムの振る舞いは、人間の直感に反する。
- バッチサイズ、要件のサイズ、リソースの稼働率は、待ち行列のサイズとサイクルタイムに非線形かつランダムな影響を与える。
- これらを理解せずに管理すると、スループットが極端に遅くなる可能性がある。
- 待ち行列のサイズは、サイクルタイムに影響を与える。
- 変動性のあるシステムでは、高い稼働率はサイクルタイムを増大させ、スループットを低下させる。
- 高い稼働率は助けにならず、むしろ害になる。
- 伝統的なリソース管理アプローチ(例:McGrath04)は、作業者の忙しさの局所最適化に注目し、システム全体のスループットを悪化させる可能性がある。
- 変動性のあるシステムにおいて、多段階のプロセスとWIPキューが連続する構造は、遅延をさらに悪化させる。
- これはまさに従来の逐次開発(ウォーターフォール型開発)の特徴。
- 多段階システムの最初のフェーズで変動性が大きい場合、サイクルタイムに最悪の影響を与える。
隠れたバッチ:バッチを見抜く目(Hidden Batches: Eyes for Batches)
チェリーパイを3つ同時に焼く場合、それが 「3つのアイテムのバッチ」 であることは明白です。
しかし、プロダクト開発ではバッチの存在がそれほど明確ではありません。
例えば、「1つの要件」とは何か? を考えてみましょう。
- 一見、「債券デリバティブ取引を処理する」という要件は単一の要件 に見えます。
- しかし、実際にはこれは複合要件(composite requirement) であり、サブ要件のバッチ になっています。

これまで見てきたように、M[x]/M/1/∞ モデルのように振る舞う待ち行列システム において、高い稼働率(high utilization rates)と変動のある大きなバッチは、サイクルタイムを悪化させる要因 となります。
また、「単一の大きなアイテム」も、実際には隠れた大きなバッチであり、サイクルタイムに悪影響を及ぼす ことがわかりました。
したがって、LeSS における待ち行列管理の示唆は以下のとおりです:
- 平均サイクルタイムを短縮するために、システム内に適度な余裕(slack)を確保する。
- 作業者を「100%稼働」させないことが重要。
- プロダクトバックログ内の「単一の大きなアイテム(要件)」を、
最終的に、段階的に、小さく、かつおおよそ同じサイズのアイテムに分割していく。
隠れた待ち行列:「待ち行列を見抜く目」を養う(Hidden Queues: Eyes for Queues)
トヨタに入社した人々は、「ムダを見抜く目(Eyes for Waste)」を学びます。
彼らは、これまで意識していなかったものをムダとして認識できるようになります。
例えば、在庫(inventory)—つまり、モノが待ち行列として滞留している状態 です。
物理的な待ち行列 は、人々が問題として認識しやすいものです。
「なんてこった!あそこに巨大な『モノの山』が溜まっているぞ!」
このとき、次のような疑問が生まれます。
- この在庫から利益は生まれているのか?
- この山の中に欠陥品が含まれていないか?
- この在庫を出荷する前に、ほかのモノと組み合わせる必要があるのか?
- そもそも、この山にある「すべてのアイテム」が本当に必要なのか?利益を生むのか?
** 見えない待ち行列(Invisible Queues)**
しかし、従来の開発プロセスには、あらゆる種類の待ち行列が存在しているにもかかわらず、それらは「目に見えない」ため、問題として認識されにくい のです。
たとえば:
- WIP(仕掛かり作業)の待ち行列
- 仕様書やドキュメントの滞留
- ディスク上の未統合コードの蓄積
これらは 物理的に積み上がるモノではないため、「ムダ」としての認識が薄い のです。
しかし、もしあなたがビジネスオーナーで、1,000万ユーロの投資をして「部分的に完了した作業の山」を作ったとしたら?
- それが床に積まれて動かない状態を見たら?
- 一円も利益を生み出していないその状態を見たら?
- その痛みと緊急性を感じるはずです。
- 「もうこんな半端な作業の山を作るのはやめよう」と考えるでしょう。
しかし、プロダクト開発の現場では、彼らは「自分たちの待ち行列」の痛みを感じることができていない のです。
「見えない待ち行列」が存在しているにもかかわらず、それが問題として認識されにくい。
開発者やチームメンバーは「待ち行列を見抜く目(Eyes for Queues)」を学ぶ必要がある。
そうしなければ、彼らは待ち行列のサイズを減らすことの重要性に気づかない。
** 目に見える待ち行列のためのビジュアルマネジメント(Visual Management for Tangible Queues)**
「待ち行列を見抜く目」を養い、問題意識を持つために、リーンの実践として「ビジュアルマネジメント(Visual Management)」 があります。
これは、コンピュータ上のデータではなく、物理的なトークンを使って待ち行列を可視化する手法 です。
たとえば:
- スプリントのすべてのタスクを紙のカードに書き、壁に貼って、完了に向けて移動させる。
- プロダクトバックログの最優先アイテムを同じように物理的なカードで管理する。
これにより、「コンピュータの中に隠れていた見えない待ち行列」が、実際に「目に見える状態」になる。
もしこの情報をすべてコンピュータの中に隠してしまったら、リーンのビジュアル(物理的)マネジメントの目的は失われる。
なぜなら、人間の進化的な本能として、「物理的なモノを見ることで、待ち行列の存在を理解し、危機感を覚える」 からである。
開発チームは、「待ち行列を見抜く目(Eyes for Queues)」を持つことで、WIPの削減とフローの改善に取り組めるようになる。
バッチサイズとサイクルタイム短縮の間接的なメリット
「なぜそんなことをする必要があるのか?うちの顧客は2週間ごとのリリースなんて望んでいないし、部分的な要件だけが欲しいわけでもない。」
この質問は、プロダクトチームやビジネス関係者からよく聞かれます。
彼らはまだ 「小さなバッチ」と「短いサイクル」の利点 を十分に理解していません。
以下のようなメリットがあります:
- 全体的なリリースサイクルの短縮
- 待ち行列を根絶し、待ち行列管理を適用することで、複数の開発サイクルを短縮できる。
- バッチ遅延の排除
- 1つの機能が不要に遅延するのは、大きなバッチの他の要件と一緒に流れているからである。
- バッチ遅延をなくせば、ビジネスは優先度の高い小規模なプロダクトを早く出荷できる自由度が増す。
- 間接的なメリット:「湖と岩」効果
- これは次のメタファーで説明される。
間接的なメリット:「湖と岩」のメタファー
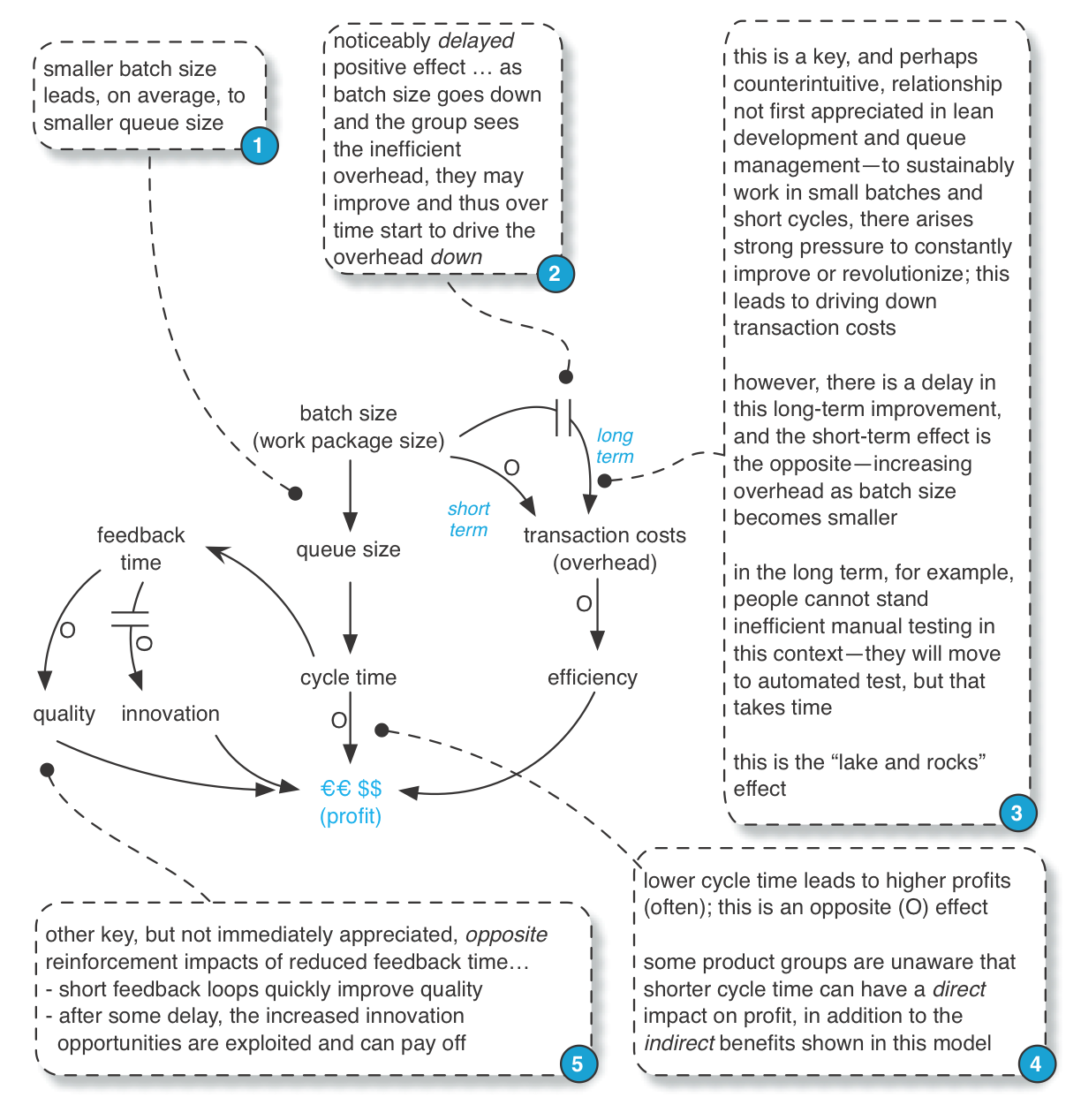
リーン教育でよく使われるメタファーに 「湖と岩」 があります。
- 湖の水の深さ → 在庫レベル、バッチサイズ、イテレーションの長さ、またはサイクルタイム を表す
- 水面下の岩 → システムの弱点 を表す
水位が高い(=大きなバッチ、長いイテレーション)と、岩は隠れて見えない。
- 例:18ヶ月の逐次開発(ウォーターフォール型)のリリースサイクルでは、
非効率なテスト、統合の遅れ、コラボレーション不足 などの問題が水面下に隠れてしまう。
しかし、水位を下げる(=バッチを小さくし、短いサイクルで開発する)と、岩が現れる。
- 例:「2週間ごとに小さなフィーチャーを出荷可能な状態でリリースしてください」 と求めると、
非効率なプロセスがすぐに明らかになり、痛みを伴う形で顕在化する。

言い換えると、従来のプロセスサイクルにおける「取引コスト」(オーバーヘッドコスト)が許容できないレベルに達する ということになる。
この痛みが改善の原動力となる。なぜなら、人々はこの苦痛を短いサイクルごとに繰り返すことに耐えられず、
そもそも従来の非効率な開発システムでは、イテレーションの目標を達成すること自体が困難になるためである。
ヒント:
すべての「岩」が大きく、すぐに目に見えるわけではない。
リーンやスクラムの取り組みは、まず最も明白で大きな「岩」から着手し、それを取り除いた後に、徐々に小さな障害へと取り組んでいく 旅である。
以下の因果ループ図(Causal Loop Diagram) は、システムダイナミクスモデルの視点から、この「湖と岩」の効果を示している(記法の説明は システム思考 を参照)。
LeSS における待ち行列管理の適用(Applying Queue Management in LeSS)
待ち行列を管理する戦略は数多く存在する。
Don Reinertsen の Managing the Design Factory では、多くの手法が紹介されている。
しかし、LeSS の文脈では、以下の重要なステップに焦点を当てる。
- システムを変え、待ち行列を完全になくす
- 残る待ち行列を可視化する(ビジュアルマネジメントを活用)
- 変動性を減らす
- 待ち行列のサイズを制限する
システムを変える(Change the System)
本当に既存の待ち行列を管理しなければならないのか?
「箱の外」に目を向けるべきである。
例えば:
- フィーチャーチームの導入
- 受け入れテスト駆動開発(ATDD)の適用
- 継続的デプロイメント(CD)の実施
これらによって、従来型開発の多くの待ち行列はそもそも不要になる。
変動性を減らす(Reduce Variability)
多くの人は、待ち行列を減らそうとするときに、
- リソースの利用率を上げる
- マルチタスクを増やす
- 開発者を追加する
といったアプローチをとるが、これらは逆効果になることが多い。
確かに優秀な人材を増やせば効果がある場合もある(例外はある)が、それにはコストと時間がかかる。
待ち行列管理を理解している人は、よりシンプルな解決策に目を向ける。
それは、特殊原因変動(special-cause variability) を減らすことである。
例えば:
- バッチサイズの削減
- 大きな要件を小さく分割
これらが、最も効果的な改善策の出発点となる。
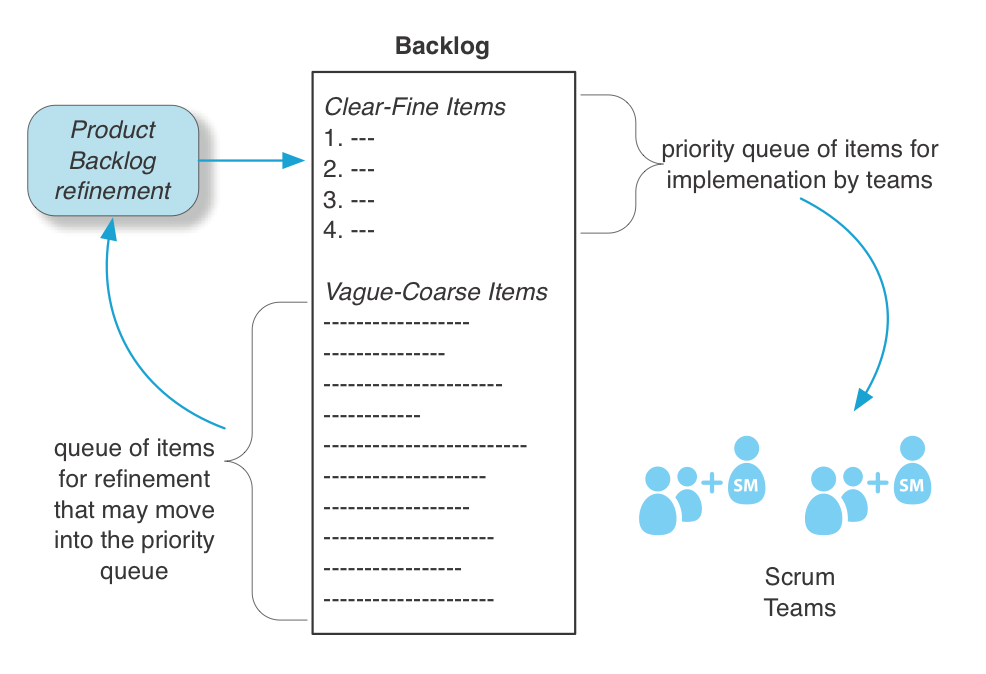
プロダクトバックログをより細かく管理する
プロダクトバックログは、一見すると 「巨大な優先順位付きキュー」 のように見える。
しかし、より詳細に分類すると、いくつかの異なるサブセットが存在する。
- 現在のリリースのためのリスト(理想的には毎スプリントがリリースサイクル)
- 将来のバックログ
また、別の視点では、以下の 2つのサブセット に分けられる。
- 「明確・細分化(clear-fine)」のサブセット
- すでに明確に分析され、適切に見積もられ、細かく分割されたアイテム
- 1つのチームが 1 スプリントよりも短い時間で実装可能なレベル
- 「曖昧・粗い(vague-coarse)」のサブセット
- まだ分析や見積もりが不十分な、粗い粒度のアイテム
- 「明確・細分化」のサブセットに入る前に、さらに分割・整理が必要
「現在のリリース」と「将来のバックログ」の両方には、「明確・細分化」 と 「曖昧・粗い」 のアイテムが混在している。
リリースサイクルの開始時点では、「現在のリリース」 には 「曖昧・粗い」 アイテムが多く含まれるが、
スプリントごとに プロダクトバックログリファインメント(PBR) を通じて 「明確・細分化」 されたアイテムへと整理される。
重要なポイント
- LeSS では、「現在のリリース」の「明確・細分化」されたアイテムのみを優先するのが一般的であり、推奨される。
- LeSS において、「明確・細分化」された優先キューこそが、チームの実装作業の中心となる。
- 「曖昧・粗い」サブセットは、プロダクトバックログリファインメント(PBR)を通じて、「明確・細分化」サブセットへと供給される。
このように待ち行列を適切に管理することで、LeSS では より短いサイクルで価値を提供し、全体のスループットを向上させる ことができる。
新しい開発を行う際に、変動性の削減 という考え方にあまりにも夢中にならないようにすることが重要である。
なぜなら、新規開発は製造業とは異なり、変動がなければ、新しいものは生まれず、発見も起こらない からである。
研究開発において変動性があることは、適切であり、避けられない ものでもある。
しかし、削減可能な種類の変動性 も確かに存在する。このセクションでは、それについて説明する。
エドワーズ・デミングの用語では、変動性には以下の 2種類 がある。
- 共通原因変動(Common-Cause Variation)
- プロセス内の一般的なノイズであり、特定の原因を特定することが難しい変動性
- 特殊原因変動(Special-Cause Variation)
- 特定できる変動(Assignable Variation)
- 例: 「要件のサイズの変動」 は特殊原因変動
- 例: 「不明確な要件を分析不足のまま作業すること」 も特殊原因変動
LeSS や作業プロセスにおいて、特定可能な特殊原因変動を減らすことで、待ち行列を持つシステムの平均スループットを向上させることができる。
リーン思考における変動性(Variability)
変動性は、リーン思考における3つのムダのうちの1つ である。
(他の2つは オーバーバーデン(過負荷) と 付加価値のない活動)。
待ち行列理論を理解することで、なぜ変動性がムダとされるのかが、より明確になる。
LeSS における変動性の要因
LeSS において、どのような種類の変動性が存在するか?
- 大きなバッチや大きなアイテム
- アイテムの意味の曖昧さ
- アイテムの設計・実装方法の曖昧さ
- 異なるアイテムごとの(見積もられた)作業量の違い
- 「現在のリリース」における明確・細分化(clear-fine)優先キューのアイテム数
- 見積もりと実際の作業量の差(what/how の曖昧さ、不正確な見積もり、学習プロセスなどが影響)
- 「現在のリリース」の clear-fine 優先キューへのアイテムの到着率
- チームや個人の作業の変動性
- テストラボなどの共有リソースの過負荷や障害発生
LeSS では、これらの変動性を適切に管理することで、開発の効率とスループットを向上させることができる。
…そして、さらに多くの要因がある。
待ち行列モデルの用語では、これらの変動性は通常、「サービス時間」と「到着率」の変動に帰着する。
リーン思考では、「フロー(Flow)」が重要な原則の一つ であり、フローを実現するには、変動性の削減または排除が必要 となる。
そのため、「平準化(Leveling)」もリーンの原則の一つ であり、変動性を抑え、フローを促進する対策として機能する。
LeSS における特殊原因変動の削減(Reducing Special-Cause Variability in LeSS)
この考え方に基づき、LeSS における特殊原因変動を削減するための具体的な提案をご紹介します。
クリアで細分化された同じサイズのユーザーストーリーをリリースバックログに小規模な待ち行列(バッファ)として保持する
トヨタでは、高品質な在庫の小規模なバッファ を用意し、後工程への作業の流れを平準化する ことを行っています。
この在庫(必要な一時的なムダ)により、LeSS のフィーチャーチームが常に同じサイズのアイテムをスムーズに処理できる環境を整え、待機時間や予期せぬ問題を減少 させます。
一方、「曖昧で粗い(vague-coarse)」サブセットにあるアイテムは、要件の「何を」「どのように」実装するかが不明確であり、サイズも大きいため、これらをそのまま実装に選ぶのは不適切です。
これが変動性を増加させる原因になるため、避けるべきです。
スプリントごとにプロダクトバックログリファインメント(PBR)ワークショップを開催する
LeSS では、スプリントごとに PBR を実施し、今後のスプリントで処理するアイテムの準備を行うことが必須 です。
これにより、以下のような効果が期待できます。
- 「何を」「どのように」実装するかの曖昧さ(what/how ambiguity)の削減
- 見積もりの精度向上(学習を通じた再見積もりの改善)
- アイテムを小さく均等なサイズに分割し、バッチサイズを削減
- バッチ遅延(batch delay)の削減
- 重要なサブ機能が、大きなバッチの一部として不必要に遅延することを防ぐ
また、この定期的な PBR により、「明確で細分化された(clear-fine)」アイテムをキューに追加するリズムが生まれ、到着率の変動性が低減 されます。
安定したフィーチャーチームの維持
LeSS では、長期的に安定したフィーチャーチームを維持すること が重要です。
これにより、チームという「サーバー」の変動性が低減 されます。
また、クロスファンクショナルかつクロスコンポーネントなフィーチャーチームを活用することで、並行処理が可能になり、フローが改善 されます。
その結果、どのチームでも同じアイテムに対応できるようになり、作業の流れがスムーズになります。
タイムボックス化・作業時間を制限した学習目標を設定する
このアプローチは、特に 「研究開発型の大規模な要件」 を扱う際に有効です。
- 「何を」「どのように」実装すべきかの曖昧さ(what/how ambiguity)の削減
- 変動性の低減
例えば、新しい機能を理解するための事前調査が必要な場合、チームに単に「このテーマについて研究してください」と依頼すると、
作業範囲が曖昧で無限に拡大し、リーンの観点から 「過剰処理(over-processing)」 のムダが発生する可能性があります。
LeSS では、学習作業に明確なタイムボックスと作業時間の制限を設定する ことを推奨します。
例えば、ブダペストでのコンサルティング事例では、あるモバイル通信プロダクトチームが
「セルラー通信でのプッシュ・トゥ・トーク機能」の開発を検討していました。
しかし、国際標準規格の文書は数千ページにも及び、全体像を理解するだけでも膨大な労力が必要 でした。
そこで、単に「研究しておいてください」ではなく、次のような具体的な目標を設定しました。
「スプリントの終わりまでに、プッシュ・トゥ・トークの概要について 30 人時(person hours)以内でレポートを作成」
このように、研究と学習に投入する作業量を制限しつつ、実装作業も並行して行う ことで、
変動性を抑え、バランスの取れた進行が可能になります。
その後、プロダクトオーナーは、さらに明確になった要件について次のスプリントで再度調査するかを決定 できます。
このプロセスを繰り返すことで、最終的に十分に理解された状態で要件を細分化・見積もりし、実装フェーズに移行 できます。
LeSS における待ち行列のサイズ削減(Reducing Queue Sizes in LeSS)
待ち行列管理のもう一つの手法として、待ち行列のサイズを制限する 方法があります。
これは必ずしも変動性を削減するわけではありませんが、別の利点をもたらします。
従来の 先入れ先出し(FIFO) の WIP キューにおいて、長いキューは大きな問題 になります。
なぜなら、アイテムが待ち行列を通過するのに非常に長い時間がかかり、最終的な完了までに遅れが生じる からです。
この単純な理由からも、FIFO WIP キューのサイズは制限すべきです。
プロダクトバックログの 「優先度キュー」 では、順番を並び替えられるため、FIFO WIP キューほど深刻な問題にはなりません。
しかし、それでも 現在のリリースにおける「明確・細分化(clear-fine)」優先キューのアイテム数を制限するべき理由 があります。
待ち行列サイズを制限すべき理由
-
細かく分割された複雑な機能のリストが長すぎると、理解しづらく、優先順位付けが難しくなる。
- 大規模プロダクト開発では、プロダクトオーナーが「バックログが大きすぎて把握しきれない」と不満を漏らすことがよくあります。
-
明確に分析され、細かく分割され、適切に見積もられたアイテムのバックログが大きいと、それ自体が「投資済みの WIP」になり、財務的なリスクを抱える。
- すべての WIP や在庫と同様に、投資した分のリターンが得られるとは限らないため、慎重に管理する必要があります。
-
時間が経つと、人は詳細を忘れてしまう。
- 「明確・細分化(clear-fine)」サブセットのアイテムは、すべて PBR(プロダクトバックログリファインメント)で詳細に分析されている。
- このリストが短い場合、アイテムを実装するチームは「最近」ワークショップで分析した可能性が高い。
- 例えば、過去2ヶ月以内に議論されたアイテムであれば、まだ詳細を覚えている可能性がある。
- 待ち行列が長くなればなるほど、チームは過去に分析したアイテムを扱う確率が高くなる。
- たとえワークショップで作成された文書があったとしても、古くなるにつれて不完全になり、チームの理解が曖昧で不確実になる。
これらの理由から、LeSS では「現在のリリース」の明確・細分化されたアイテムのキューサイズを制限することが推奨されます。
結論(Conclusion)
待ち行列管理は、「ハンマーを持つと、釘を探したくなる」 ようなものになりがちです。
つまり、すでに存在する待ち行列を管理することに意識が向いてしまう 可能性があります。
しかし、これは 「箱の中(inside-the-box)」での解決策 です。
本来の目標は、システムカイゼン(system kaizen)を行い、そもそも待ち行列が発生しないようにシステムを変更すること です。
例えば:
- クロスファンクショナルチームの導入
- 受け入れテスト駆動開発(ATDD)の活用
- 並列処理の促進
などのアプローチがありますが、これ以外にも多くの方法が考えられます。
待ち行列を完全に排除できない場合にのみ、「待ち行列管理」というポイントカイゼン(point kaizen)の戦術を適用するべきです。
推奨書籍(Recommended Readings)
待ち行列理論に関する一般的な書籍は数多く存在しますが、
プロダクト開発と待ち行列理論の関連を明確に説明した書籍 を以下に紹介します。
1. 『Managing the Design Factory』 - Don Reinertsen
- 待ち行列理論とプロダクト開発の関係を説明したクラシックな入門書。
2. 『Flexible Product Development』 - Preston Smith
- 広く普及したプロダクト開発の書籍で、アジャイル開発(Scrum, XP)を一般の読者に紹介した最初の書籍の一つ。
- 待ち行列理論や変動性の分析が含まれ、それが開発に与える影響についても詳しく解説。
これらの書籍を参考に、LeSS における待ち行列管理とシステム改善について、より深い理解を得てください。